Yearly review
Our top learnings from Computer Vision 2022
Dec 31, 2022

It's already been a year since our last update on our top learnings from 2021, and a lot has happened in the Computer Vision field since then. 2022 has seen even more exciting advancements and breakthroughs, and at Pento, we've had the opportunity to put many of these to use in our projects.
In this article, we'll share the techniques, topics, and resources that have impacted our work this year. We'll delve into the latest applications of diffusers in computer vision, discuss techniques for improving object detection models, and share the latest progress in deep metric learning.
As always, this is by no means an exhaustive list of all the trends and developments in the field, but we hope it will serve as a useful guide for those looking to stay up-to-date on the latest in machine learning. If you have any questions or comments, don't hesitate to reach out!
Latent Space Diffusion

This is by far the hottest topic in machine learning of 2022. You cannot talk about AI progress this past year without mentioning Latent Space Diffusion. But where did it come from, and what did the big breakthrough entail? Well, let’s take a look.
Diffusion actually appeared back in 2015 (I can’t believe this is thought of as “old”), but most people just heard of it. The main idea is that images are blurred with Gaussian noise, and the model learns how to denoise those images, thus, learning how to reverse the diffusion process. Basically, the model consisted of a sequence of autoencoders. So, what happened in 2022 that revolutionized the industry?
Latent Space Diffusion has a more sophisticated process, and it’s composed of three parts:
Text Encoder: It converts the input into embeddings. The Stable Diffusion model that was initially released used ClipText. The paper mentioned Bert and Stable Diffusion uses OpenClip. So, Transformer text models can vary, but the bigger the model, the better quality that is obtained from the image generation.
Denoising UNet + Scheduler: It takes the noise tensor or embedding and outputs an array containing information. How? Well, the UNet takes noisy, compressed images (latent) as inputs and adds the noise and embeddings in the attention layers between the ResNet blocks. By doing this, the information is merged into the latent.
Autoencoder’s decoder: This part is tricky to put down to earth, but we’ll do our best to keep it simple. The autoencoder’s encoder is in charge of converting the input image into a lower dimensional space. This learned process can be reversed to turn noise into an image. That's it! That’s how the autoencoder’s decoder is capable of generating quality images.
Back in January 2021, when OpenAI released DALL-E we could tell something huge was coming. Then DALL-E 2 appeared in April 2022, and everyone went crazy with its amazing results, but being open source and running it on a “normal” GPU made Stable Diffusion the hottest topic of 2022.
Latent Stable Diffusion allowed anyone with access to a GPU with at least 10GB of memory to play with its features: text-to-image and image modification. And the capabilities go as far as your mind — from illustrations for a children’s book to combining great painters' masterpieces.
We played around with this technology to create Songdle and Pictorial. Songdle is a game that leverages Stable Diffusion to mimic the iconic Wordle game but with songs. Pictorial allows businesses to create visuals for their site/socials/blog effortlessly by scanning their website content to create personalized prompts describing website illustrations that are fed into an image generation model.
YOLOv7
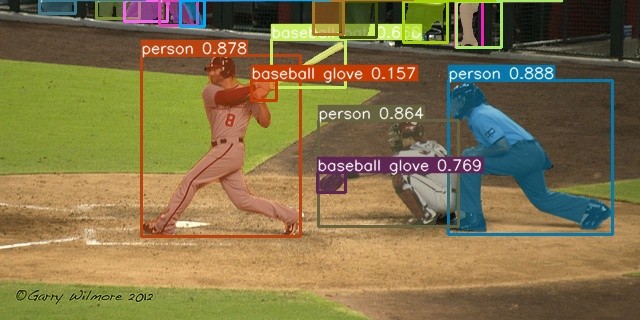
Object detection is a Computer Vision problem that aims to determine which objects are present in an image and where they are. The research on this topic started decades ago, with classic Computer Vision techniques, and had a huge breakthrough when FasterRCNN appeared in 2015. YOLO architecture also appeared around that time. It wasn’t until a few years back that YOLOV3 and then YOLOv5 became popular for object detection challenges. In 2022, different enhancements have been made over the years, with YOLOv7 appearing this year to challenge YOLOv5’s object detection throne.
So, let’s dig into what makes the YOLO family so special. Until YOLO, deep learning object detection models worked in two steps: proposing a bounding box first and then determining whether there was an object in that bounding box and which one it was. To speed up the inference time, YOLO appeared with a single-step logic, where the image was divided into a grid, and predictions were made on each grid box. Then they were filtered using a non-maximal suppression algorithm.
In the following years, many enhancements were made, leading to YOLOv5. By introducing anchor boxes, bottleneck CSP, and mosaic augmentation, they became one of the industry's most widely used object detection algorithms. Also, unlike previous versions, it is a Python open-source model, which meant it was easily deployed into production. But the improvements didn’t stop there. In 2022, YOLOv7 appeared to push the boundaries of object detection even more.
YOLOv7 is the current state-of-the-art in object detection, maintaining similar inference speeds to YOLOv5. But what distinguishes it from its predecessor? Well, let’s go through each key aspect:
Model scaling: YOLO models already came in families, varying the networks’ depth and width to achieve different results, but YOLOv7 took this to the next level by also concatenating layers together. By doing this, they managed to scale the model while maintaining an optimal model architecture.
Re-parametrization: Some modules of the layer are re-parameterized to average the model weights and create a more robust model. But not all modules can be re-parameterized. YOLOv7 manages to re-parametrize plain convolutional and ResNet modules.
Auxiliary head: Usually, models have a bunch of layers and finish with a head that finishes the work by outputting the desired result. In YOLOv7, they added an auxiliary head before the end of the network and determined that a coarse-to-fine with different levels of supervision improved the model's performance.
Bag-of-freebies: This idea is not new to the YOLO family, having appeared already in YOLOv4. Training strategies are applied to improve the model's performance without increasing inference times: data augmentation, semantic distribution bias in the datasets, and objective function of bounding box regression.
This way, the authors of YOLOv7 created more complex models requiring longer training time but having similar inference times than comparable models like YOLOv5. It is particularly interesting that with the years, deep learning has not only evolved due to new architectures but also because of the preprocessing that is done to the data, the augmentations a key aspect for training a robust Machine Learning model.
Deep Metric Learning
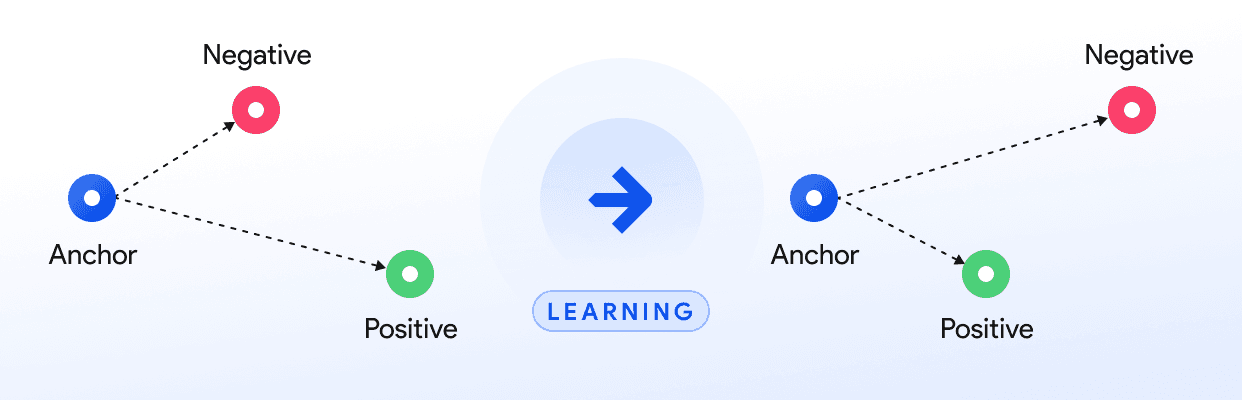
Deep Metric Learning (DML) is a recurrent research topic at Pento, as it is applied to tackling different types of challenges. Last year we reviewed a couple of learnings on leveraging global information to build better embeddings using DML. We also share wrote some articles on how to get started with DML using the popular library Pytorch Metric Learning. This year we will review two ideas, one that directly impacted our results and another that will greatly impact and define the direction of future research.
Integrating Language Guidance into Vision-based Deep Metric Learning
This paper proposes a framework to harness the power of Large Language Models (LLMs) to incorporate language high-level semantics into the embedding generation using the DML approach. Usually, supervised DML uses class labels and contrastive objectives to build embeddings. These approaches fail to capture the high-level language semantics between classes that contain much information useful to understand the relationship between images.
The increasing capabilities of LLMs will facilitate significant advancements in vision models. This will be a prominent area of focus in 2023, resulting in many innovative developments.
The authors propose two approaches:
Expert Language Guidance (ELG) This approach is used to better align visual representations with language semantics. This is done by using large pre-trained language models (such as CLIP, BERT, or RoBERTa) to map an input sentence to generate language embeddings. These sentences represent the ground truth class labels. Then the respective similarity matrixes are created and compared using KL-Divergence matching. The matrixes are then adapted to ensure intraclass resolution.
Language Guidance without extra supervision It uses the pretrained backbone and classifier head of the ImageNet dataset to produce softmax outputs that correspond to all ImageNet classes. These outputs are then averaged for each class. The top-k ImageNet pseudo-class names are then selected to represent the image. The language network is then used over the pseudo labels to provide approximate semantic context. This can be done sample-by-sample to capture the semantic differences between images of the same class. Ultimately, this helps the algorithm align image representations to the multiple class concepts related to the image.
Hyperbolic Vision Transformers: Combining Improvements in Metric Learning
Another approach we researched to get better embeddings is hyperbolic vision transformers. Yes, we know that this part initially sounds like a bunch of fancy words, but we swear we’ll do our best to bring it back to the real world. There are three keys to understanding what goes on here: the architecture, the embedding space, and the loss. Let’s break down each of them.
Vision transformers
https://arxiv.org/abs/2010.11929
This is how the embeddings are formed initially. This is turning the image into 16x16 patches, flattening, projecting into an embedding, concatenating, a token is added for the associated class, and, finally, this is passed through the encoder of the transformer to obtain an embedding. In a few words, vision transformers are used to transform the image into an embedding.
Hyperbolic embeddings This concept might feel more abstract to many people, but again, we’ll do put best. There are different types of spaces. The “normal” one is Euclidean space. But it is not the only one.
We are referring to the hyperbolic space projected over a Poincaré ball. Let’s imagine a plain 3D ball to understand some concepts versus a cube for euclidean spaces. When you increase the volume, the ball scales exponentially with the radius, while the cube does so polynomially with the side. An analog concept happens with trees. So, we can imagine that data can be embedded hierarchically with lower dimensions in a hyperbolic embedding space.
Ok, that one was tough, but as long as we got the idea that it allows us to have more efficiently distributed embeddings, we will be fine.
Pairwise cross-entropy loss
This part is quite straightforward. The pairwise cross-entropy loss has one key characteristic that makes it ideal for this kind of job: since it is computed by comparing one pair of data points, it means that it operates directly on the embeddings. Unlike other losses that operate over a subset of data altogether, the pairwise cross-entropy loss performs better when dealing with data points with subtle differences.
These three techniques work together to be used with low supervision, which is usually a big deal on machine learning projects.
Our predictions for 2023
We expect further progress in diffusion models, getting better results and performance. But our bet for 2023 is on combining language and vision. We have already seen how it could be applied to boost existing topics such as Detic in object detection and Language guidance in DML (described above).
stay in the loop
Subscribe for more inspiration.
